天翼云代理,天翼云代理商,北京代理商
天翼云2.5折专线:18510009100/18510009200(全国市话)
在较早的文章中介绍了些Volcano/Cascades优化器结构的规划理念和完结思路,根本是依据论文的解读:
虽然cascades号称现在最为先进的优化器查找结构,但不得不说这2篇paper的内容,实在是让人看起来有些费劲。尤其是后篇,说是从工程完结的视点来描绘,但解说的不行翔实,并且有些当地既含糊又笼统。
此外工业界并没有一款优化器是彻底依据paper的结构去完结的,这让我们按图索骥变得愈加困难,不过今天介绍的这篇paper 《EFFICIENCY IN THE COLUMBIA DATABASE QUERY OPTIMIZER》,为理解cascades供给了很好的参阅,并且供给了开源完结。
归纳来说,这篇paper详细解说了columbia optimizer的规划和完结,它彻底参阅了cascades中的概念和top-down的查找战略,并做了一系列优化来改善cascades的优化功率。
本文将分为以下几个方面进行介绍:
查询优化的本质,是
给定query和价值模型等元信息的前提下,查找计划空间的一切或许,得到价值最低的履行计划。
这是一个NP hard问题,人们通常会运用dynamic programming的思维,将其转化为一个problem和其包括的一系列嵌套的subproblems。经过递归获取子问题的最优解并向父问题延伸,终究得到根问题的最优解。
cascades的优化结构也遵从了这个思路,只不过与system-R等不同,它不选用子problem -> 父problem的直观道路,而是从父problem -> 子problem深度优先递归办法,也便是所谓的top-down search strategy,并在进程中运用memorization防止对相同子problem的重复核算。深度优先的好处是能够尽早获取到一个可行的物理计划和对应cost,并以该cost作为上界在后续search中做剪枝。
关于cascades这儿只大约给出一些根本概念,便利理解文章后续的内容,总的来说仍是需求读者有cascades的根本理论知识,详细的内容能够参见前面的文章或读原paper。
描绘某个特定的algebra运算,关于联系代数便是例如join / aggregation等。分为logical/physical两类
在计划空间中描绘一个详细的algebra运算内容的数据结构,假如是联系代数那就标明一个联系运算表达式。内部会包括对应该运算的operator,依据operator的不同类型分为logical expression/physical expression。一般一个logical expression会对应多个详细完结的physical expressions。
运算成果所具有的逻辑特点,这类特点与运算的语义相关,与详细完结无关,例如数据的cardinality/schema等。
运算成果所具有的物理特点,这类特点与详细完结办法相关,例如数据的collation(次序)/distribution等。
上面提到了优化的进程是对problem/subproblems的求解,由于问题的杂乱性,dynamic programming会对problem做必定的“拆分”,而group便是按照逻辑等价性进行拆分的成果,不同group对应不同的subproblem,然后把问题规划不断减小。
详细到完结中,group是一切逻辑上等价的expression的调集,其间一切expression(包括logical expression + physical expression)的逻辑特点相同,构成逻辑等价类。
寄存优化进程中一切枚举的计划的数据结构,跟着优化进程的进行会生成若干潜在的候选plan tree,内部会运用memorization来防止生成重复的计划内容,削减无谓空间/时刻浪费。
search space是依据group来组织的,一切各类expression包括在所属group内部。所以组织层次上是
search space -> group -> m-expr
rule是查找算法中最为中心的部分,各种计划(节点)的生成是经过rule来完结的,rule总是运用到一个logical expression上,将其转化为另一种logical expression或许一个physical expression。
logical -> logical的转化,称为transformation rule。
logical -> physical的转化,称为implementation rule。
无论是哪种rule,都包括两个最首要的结构:
因而一个rule是否能够运用,要判别Pattern是否和现有的expression tree能match上,能够的话,就把substitute对应的新expression tree树立起来,参加search space中,作为候选计划的一部分,然后完结对计划空间的扩展。例如,一个transformation rule是predicate pushdown,那它所要求的pattern就必须是
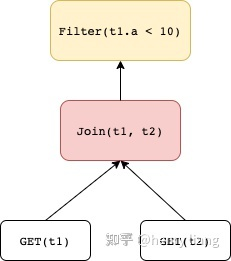

假如expression tree上是join -> join,则不满意这个pattern而无法运用这个rule。转化后的substitute为右图
由于cascades的查找进程是top-down的,这意味着对当时的expression tree优化时,总是先处理root expression,一旦确认了其物理履行算法,会向children做递归优化,这时root expression的物理完结或许会对children的输出物理特点有所要求,例如top join假如运用sort merge join,则要求2个input在对应的join key上是有序的,这种对物理特点的要求构成了optimization goal的一部分。
enforcer是一个physical operator,作用是改动input group的物理特点,来满意上层算子的要求。
这节参阅了paper的首要内容,侧重介绍search engine的规划完结和相对cascades关于查找功率的改善。
三大组件:
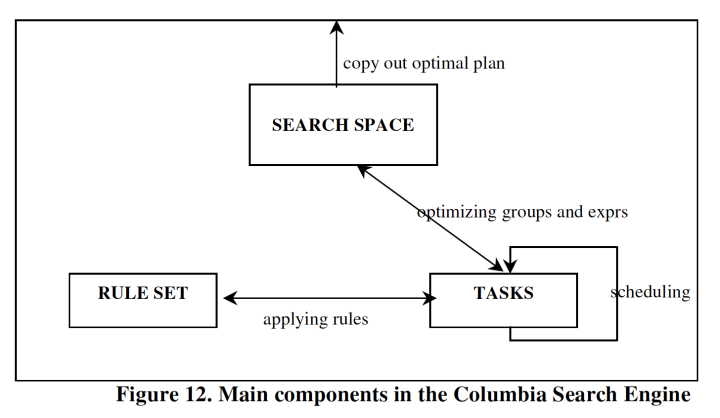
这儿的根本思路和cascades一样,经过不同类型的task来驱动整个优化流程,扩展seach space,task的中心是对rule的运用。
首要介绍一个columbia optimizer中的重要概念,multi-expression:
一个query在经过parser后会被转化为由expression(缩写expr) 组成的AST,而multi-expression(缩写m-expr)则是expr的"紧凑"版别,两者同享了描绘运算语义的operator方针,但expr的输入是子expr,而m-expr的输入则是子group,其内部是恣意满意该运算语义的m-expr调集,例如关于表达式:
(t1 inner_join t2) inner_join (t3)
其left input是 (t1 inner_join t2),但这仅是一个逻辑运算符,内部或许对应
t1 inner_join t2 / t2 inner_join t1 / t1 hash inner join t2 / t2 nested loop inner join t1 .....
等许多的详细表达式(logical/physical),但都属于同一个group。
m-expr是group中的首要组成成员,优化进程也首要依据m-expr进行。
在构建初始search space时,会把parser生成expr tree CopyIn search space中,形成一系列basic groups,这些group中只要一个initial logical m-expr,与AST中的expr一一对应。后续优化中,group中的m-expr会不断添加,或许search space中发生新的group。
SSP (Search Space,对应Memo) |-> groups (array) |-> m-exprs |-> operator (logical/physical) |-> input groups (array)
代码中几个首要结构类和内部一些重要成员:
class SSP //Search Space
{
public:
M_EXPR ** HashTbl; // To identify duplicate MExprs
// Convert the EXPR into a Mexpr.
// If Mexpr is not already in the search space, then copy Mexpr into the
// search space and return the new Mexpr.
// If Mexpr is already in the search space, then either throw it away or
// merge groups.
// GrpID is the ID of the group where Mexpr will be put. If GrpID is
// NEW_GRPID(-1), make a new group with that ID and return its value in GrpID.
M_EXPR * CopyIn(EXPR * Expr, GRP_ID & GrpID);
//If another expression in the search space is identical to MExpr, return
// it, else return NULL.
// Identical means operators and arguments, and input groups are the same.
M_EXPR * FindDup (M_EXPR & MExpr);
private:
GRP_ID RootGID; //ID of the oldest, root group. Set to NEW_GRPID in SSP""Init then
//Collection of Groups, indexed by GRP_ID
CArray Groups;
}; // class SSP
class GROUP
{
public:
GROUP(M_EXPR * MExpr); //Create a new Group containing just this MExpression
inline GRP_ID GetGroupID() {return(GroupID); };
//Return winner for this property, null if there is none
WINNER * GetWinner(PHYS_PROP * PhysProp);
//Create a new winner for the property ReqdProp, with these parameters.
//Used when beginning the first search for ReqdProp.
void NewWinner(PHYS_PROP *ReqdProp, M_EXPR * MExpr, COST * TotalCost, bool done);
private :
GRP_ID GroupID; //ID of this group
M_EXPR * FirstLogMExpr; //first log M_EXPR in the GROUP
M_EXPR * FirstPhysMExpr; //first phys M_EXPR in the GROUP
LOG_PROP * LogProp; //Logical properties of this GROUP
COST * LowerBd; // lower bound of cost of fetching cucard tuples from disc
// Winner's circle
CArray < WINNER *, WINNER * > Winners;
}; // class GROUP
class M_EXPR
{
private:
M_EXPR * HashPtr; // list within hash bucket
BIT_VECTOR RuleMask; //If 1, do not fire rule with that index
OP* Op; //Operator
GRP_ID* Inputs;
GRP_ID GrpID; //I reside in this group
inline int GetArity() {return (Op -> GetArity()); } ;
//We just fired this rule, so update dont_fire bit vector
inline void fire_rule(int rule_no) { bit_on( RuleMask , rule_no); };
}; // class M_EXPR
class WINNER
{
private:
M_EXPR * MPlan;
PHYS_PROP * PhysProp; //PhysProp and Cost typically represent the context of
COST * Cost; //the most recent search which generated this winner.
bool Done; //Is this a real winner; is the current search complete?
}; //class WINNER
search space的总体规划与cascades没什么不同,但做了如下改善
为了进步查找功率,针对group做了2点改善
在top-down的优化中,详细到某个group时,会有对应的search context(cascades中的optimization goal),context中包括2个部分:
[required physical property , cost upper bound]
也便是在向下查找时,要求当时group输出的物理特点,一起整个子计划的价值要小于cost上界。
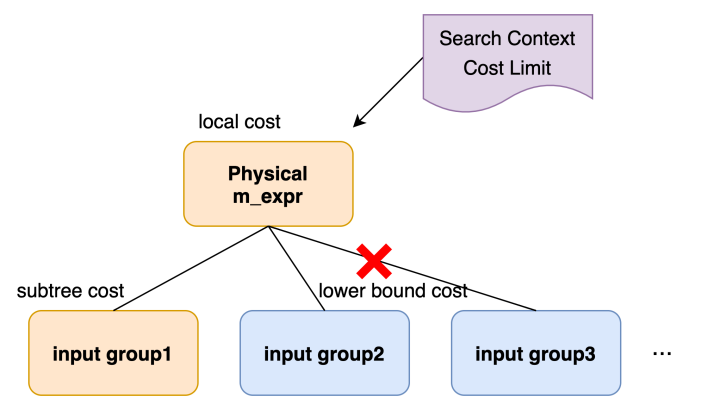
子计划的价值是当时group的physical m-expr价值 + 各个input group中最优physical m-expr的价值。有没有或许在优化input group之前,就能判别其价值现已过大了,然后完结pruning呢?
columbia为每个group核算一个cost lower bound,并确保group枚举的任一physical m-expr对应的子plan,其cost(m-expr) > lower bound。这个lower bound是依据group的logical property核算的,和详细算子完结办法无关,在group创立时核算完结。
剪枝进程如下图,top group的physical m-expr已生成并可得到该算子的local_cost,在顺次优化基层input group时,假定input group1已优化完得到subplan cost1,而input group 2/3没有优化,但此刻
top local cost + input cost1 + input_group2's lower bound cost > Cost Limit
标明无法找到满意context的最优解,然后防止了对input group 2/3的无意义优化。
lower bound cost的详细算法如下:

|G| = group输出的cardinality
cucard(Ai.X) = Ai.X这列在G的输出成果中具有的最大NDV值
cucard(Ai) = max(cucard(Ai.X)) 标明关于一切在G输出成果中的Ai表的列,具有的最大NDV值
touchcopy() = 对一行join成果做拼接并copy出去的价值
Fetch() = 经过IO读取一行数据的价值
这个公式给出了一个join plan的总价值:
LowerBound(join sequence) = cost(top join) + cost(non-top join) + cost(base table fetch)
关于cost(non-top join)的部分,我们考虑t1 join t2 ... join tn 这个序列,且以left-deep tree为例:
non top join = t1 join t2 ... join tn-1
假如t2在G中具有cucard(t2)个NDV值,阐明t1 join t2至少发生了cucard(t2)行数据,对t3...tn-1也同理类推,由于核算的是下界,这是安全的。paper中证明了即便不是left-deep tree这个推导也树立,这儿不再胪陈。
Lower bound pruning是columbia对优化功率的一个重要改善,能够很好的进步剪枝功率,缩短优化时刻,一起由于是依据价值模型核算的cost下界,这种pruning并不影响成果的最优性。
2. 将logical m-expr和physical m-expr别离到2个链表中
在cascades中,一切m-expr是保持在一个link list中,而columbia则分为了logical/physical两个list,这在2种情况下有益:
2.1 优化一个group时,会对一切logical m-expr做rule binding的操作,假如是一个list则要跳过physical m-expr,考虑到group中的m-expr或许许多,并且physical m-expr数量会是logical m-expr的N倍,因而或许引发较多memory page fault。而rule binding是一个密集操作,因而微小的改善也有意义。
2.2 一个group或许会依据不同的search context(例如不同required physical property)重复被优化,因而将之前生成的physical m-expr保存在一起,当下次优化时能够先检查是否现已有physical m-expr能够满意新context的要求,假如能够则直接进入针对该m-expr的优化流程。而在cascades中,每个group并不特别处理physical m-expr,总是要对一切logical m-expr重新优化来生成physical m-expr,这显然不行高效且浪费空间。
由于group会依据不同search context重复优化,因而每个context应该都会找到一个最优plan,这些plan就保存在group的winners数组中,以备后续复用。
在columbia中,WINNER结构被简化,只包括
[当时group中最优的(physical) m-expr + 最优plan cost + required physical property]
在依据当时search context查找进程中得到的最优解(临时)也会保存在winner结构中。此外,假如最后无法找到满意要求的plan,这个winner方针依然会创立出来,只不过其间的m-expr是null pointer,标明无法找到context的最优解,这也是一种成果,能够保存下来被复用。
前面现已提到了EXPR和M_EXPR,以及何时从EXPR生成M_EXPR。相关于cascades中用来描绘该结构的EXPR_LIST,columbia的M_EXPR要愈加精简。
留意在上面代码中M_EXPR类的这个字段
BIT_VECTOR RuleMask; // 每个rule对应一个bit,假如fire过则设为1
RuleMask完结了columbia中的unique rule set原则,也便是关于一个m-expr,任一个rule只会对其fire(测验apply)一次,不会做重复的核算,这关于进步查找功率很重要,一起能够确保不会生成重复的physical m-expr。但留意logical m-expr的仅有性只经过unique rule set是无法确保的,由于或许有不同的logical m-expr经过不同的transformation rule生成相同的logical m-expr。因而需求在整个search space中树立logical m-expr的去重机制。这经过SSP的
M_EXPR ** HashTbl; // To identify duplicate MExprs
这个成员完结,这是一个针对logical m-expr的hash table
其key是[operator name, operator parameters, input group numbers],value便是对应的m-expr pointer。
hash table的完结依然是静态的buckets + linked list,仅仅做了2点改善:

考虑到logical m-expr的生成是个十分频繁的操作,结构的精简+查找功率进步是不错的空间/时刻优化。
rule是对m-expr进行优化的首要东西,rule和search space的界说、search strategy的界说是正交的,因而能够独立的进行扩展。
在columbia中,rule的基类界说如下:
class RULE
{
private :
EXPR * original; // original pattern to match
EXPR * substitute; // replacement for original pattern
//"substitute" is used ONLY to tell if the rule is logical or physical,
// and, by check(), for consistency checks. Its pattern is represented
// in the method next_substitute()
CString name;
BIT_VECTOR mask; //Which rules to turn off in "after" expression
int index; // index in the rule set
public :
bool top_match (OP *op_arg)
{
assert(op_arg->is_logical()); // to make sure never O_EXPR a physcial mexpr
// if original is a leaf, it represents a group, so it always matches
if( original->GetOp()->is_leaf()) return true;
// otherwise, the original pattern should have a logical root op
return ( ((LOG_OP *)(original->GetOp()))->OpMatch((LOG_OP *)op_arg) );
};
virtual int promise ( OP * op_arg, int ContextID)
{ return ( substitute->GetOp()->is_physical() ? PHYS_PROMISE : LOG_PROMISE); };
virtual bool condition ( EXPR * before, M_EXPR *mexpr, int ContextID)
{ return true; };
//Given an expression which is a binding (before), this
// returns the next substitute form (after) of the rule.
virtual EXPR * next_substitute (EXPR * before, PHYS_PROP * ReqdProp)=0;
}; // RULE
其间最重要的结构便是original(pattern)和substitute,他们都是用EXPR来构建的tree(logical operator的tree)。
在其间有一种特别的operator: leaf operator,他是expr tree的叶子节点,起到通配作用,能够match恣意子表达式。例如inner join的结合律:
RULE EQJOIN_LTOR Pattern: ( L(1) join L(2) ) join L(3) Substitute: L(1) join ( L(2) join L(3) )
其间L便是leaf operator,在APPLY_RULE这个task中,会进行pattern match,树立rule和top m-expr的绑定联系(rule binding),然后经过substitute来生成新的m-expr/group方针,参加search space中。详细包括2个首要函数:
此外,RULE方针还有些办法辅佐这个apply进程:
依然以上面的EQJOIN_LTOR结合律为例
Pattern: ( L(1) join L(2) ) join L(3) Substitute: L(1) join ( L(2) join L(3) ) Target m-expr: (G7 join G4) join G10
针对每个group,会创立一个BINDERY方针,担任将pattern与该group中一切logical m-expr做binding。
本例中
L(1) join L(2) <=> G7 join G4
L(1) join L(2) <=> G4 join G7
3. 另一个group bindery方针对right input group做检查,但只会树立一个binding
L(3) <=> G10
详细绑定算法用一个依据3个状况的有限状况机来完结,并经过BINDERY::advance()办法来驱动,不断寻觅binding:
typedef enum BINDERY_STATE
{
start, // This is a new MExpression
valid_binding, // A binding was found.
finished, // Finished with this expression
} BINDERY_STATE;
advance的伪代码如下:

根本思路便是深度优先的办法,不断找input group中的binding,再回来上层group找,直到top m-expr,详细到m-expr的匹配则是比较operator的id和arity,可参阅完结源码。
前面现已提到enforcer是一种physical operator,因而enforcer rule也算是implementation rule,会生成对应的enforcer m-expr,属于physical m-expr,其input group便是原来的group,仅仅改动了physical property。例如SORT_RULE是一个enforcer rule,在substitute中会以QSORT这个operator作为top operator,即:
SORT_RULE Pattern: L(1) Substitute: QSORT L(1) L(1) 是恣意leaf operator
只且仅当group的search context中有physical property requirement时,enforcer rule才会被考虑(promise > 0)。
关于enforcer rule的处理在columbia和cascades中十分不同:
在cascades中,search context中会包括额定一项:excluded properties,即制止生成某种物理特点,这是为防止重复apply enforcer rule而发生多个冗余的enforcers,但不同的search context下依然会生成多个对应physical property要求的enforcer。
在columbia中,enforcer rule被参加到RuleMask傍边,这样经过unique rule set机制能够防止重复生成enforcer,但也带来了一个问题:group第一次被优化后生成了enforcer m-expr,后续假如依据不同search context再优化,就无法再生成新的enforcer导致计划空间枚举不全。columbia经过复用enforcer m-expr来处理该问题。
2. 复用enforcer m-expr
在cascades中,enforcer的operator包括参数,例如QSORT(A.x) 和 QSORT(A.y)是两个不同的enforcer m-expr,都会生成在group中,应对不同context的物理特点要求。
在columbia中,enforcer的operator不包括参数,仅仅行为描绘,这样一个group只会有一个enforcer m-expr,一起在优化group时,必定要对一切已有的physical m-expr检查是否满意物理特点要求,这时假如遇到enforcer m-expr,则忽略参数以为可满意,然后进入physical m-expr的优化流程,这儿会对enforcer m-expr和其输入重新核算cost,假如是最优plan则记入winner中。后续能够从WINNER类的physical property成员补全对enforcer的完好描绘,弥补parameter的缺失。
这种处理计划有些tricky,但也削减了enforcer m-expr的数量,节约空间。
task是查找进程的使命单元,现有task的履行会创立和调度新的task。每个task都对应着当时优化的search context。对task的介绍也是对整个优化流程的介绍,这儿仍会结合代码。
class TASK
{
friend class PTASKS;
private :
TASK * next; // Used by class PTASK
protected :
int ContextID; // Index to CONT::vc, the shared set of contexts
int ParentTaskNo; // The task which created me
public :
virtual void perform ()=0; //TaskNo is current task number, which will
}; // TASK
class PTASKS
{
private :
TASK * first; // anchor of PTASKS stack
public :
void push (TASK * task);
//##ModelId=3B0C085D016B
TASK * pop ();
}; // PTASKS
一切详细task都是TASK的子类,和cascades paper中一样,task以stack的办法来调度。有了这种笼统,优化的流程实际很简略:
void SSP::optimize()
{
//Create initial context, with no requested properties, infinite upper bound,
// zero lower bound, not yet done. Later this may be specified by user.
PTasks.push (new O_GROUP (RootGID, 0, 0));
// main loop of optimization
// while there are tasks undone, do one
while (! PTasks.empty ())
{
TaskNo ++;
TASK * NextTask = PTasks.pop ();
NextTask -> perform ();
}
} // SSP::optimize()
在columbia中,task共分为5种,其相互调用联系如下:
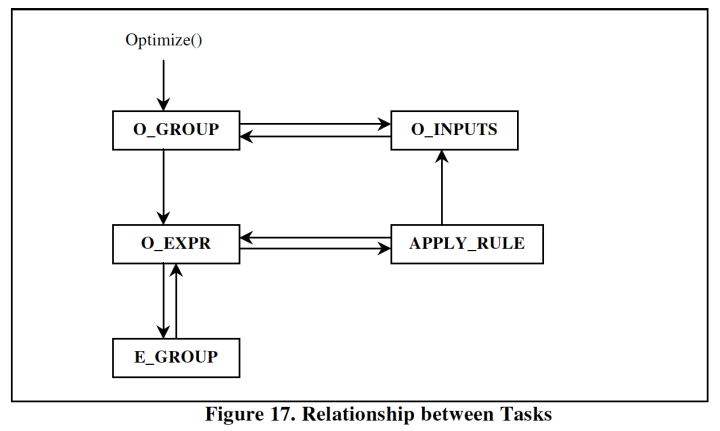
这是对plan/subplan做优化的最外层入口,会找到在特定search context下,这个group作为root的最优plan,保存到group的winner数组中。它会生成一切必要的logical/physical m-expr,并核算cost。伪代码如下:

假如未优化过则分别对logical / physical m-expr做优化:
留意这儿O_INPUTS是后入栈的,因而会先履行,依然是为了尽快发生physical plan。
在整个优化流程中,O_GROUP会在2种情况下出现:
前面介绍rule pattern match时看到,假如对应input group的sub-pattern是一个leaf operator,那总是能够匹配,但假如不是(包括其他operator),则假如想在对应的input group中获取一切binding,需求获取其间的logical m-expr进行比较,这便是E_GROUP task要完结的作业。这儿其实是cascades paper中讲述最含糊的当地,但思维很简略,便是在有需求做pattern match时,为了尽或许找到一切rule binding,对input group做exploration,生成一切logical m-exprs。

这儿经过符号完结memorization,确保group只被explore一次。另外在代码中,不需求对每个logical m-expr做O_EXPR,只需求对第一个logical m-expr即可。
在cascades paper中,E_GROUP task会创立E_EXPR task,标明对已有logical m-expr运用一切transformation rules,但由于和O_EXPR的作业有重合,columbia中去掉了E_EXPR兼并为O_EXPR,经过exploring这个符号标明只做tranform不做implement。
在columbia中,两种场景会树立O_EXPR task:

首要要搜集rule set中能够fire的rules:
然后针对排好序后的rules,顺次
留意这儿E_GROUP后入栈,因而先深度递归完结了exploration后,再履行APPLY_RULE,task中一切subtree的logical m-exprs已生成,直接查找binding即可。
rule总是apply到logical m-expr上,依据rule的类别生成logical/physical m-expr,前面现已讲过依据bindery的根本流程,这儿看下伪代码:

首要经过RuleMask防止重复apply。然后循环调用root BINDERY::advance()获取下一个binding。这儿还会对rule做一下condition的检查,不满意则不apply,不然调用next_substitute获取新的m-expr并参加search space中:
在implementation rule运用后能够得到top operator的详细物理完结,但优化还要递归到一切inputs来获取整个subtree的物理plan,这便是O_INPUTS的作业。它核算每个input group中,针对context的最优physical plan,把cost不断累加,终究得到整个subtree的plan,假如plan cost是针对该context的现在最小值,则记入到winner中。
O_INPUTS也是columbia中运用pruning战略的当地,首要包括2种:
伪代码:

在代码中经过Pruning / CuCardPruning / GlobepsPruning 3个符号敞开3档剪枝战略:
能够看到核算cost的进程是对每个没有优化过的input group,触发O_GROUP task得到基层最优解并记录在InputCost[]数组中,一起累加到CostSoFar,积极判别CostSoFar > upper bound来做pruning。
当以该physical m-expr为root的plan优化完结后,判别是否search context中的当时最优解,是则替换winner中原最优解。
至此整个search流程就整理完了,整体仍是比较明晰的:
假如大家有爱好能够去看下Columbia的代码,由于是实验项目比较简略易懂。
Calcite是产业界(尤其大数据范畴)运用十分广泛的CBO查询优化器,也是为数不多的依据volcano/cascades的完结。但在粗读其代码和检查一些技术资料后,发现前期版别中的VolcanoPlanner并不是一个严厉依据cascades论文的完结,更像其前期原型Exodus的计划。大致来说,便是查找路径并不具有top-down的规矩,而是“随机”落在search space的某个RelNode上。
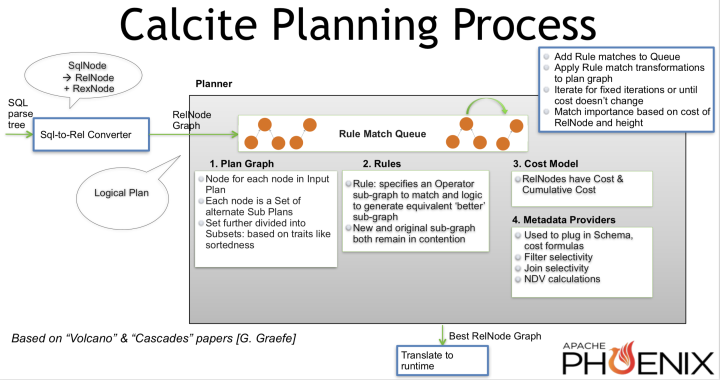
从代码上看便是对RuleMatch(rule binding)的apply不是以RelSet/RelSubSet为单位从上到下的进行,而是大局同享一个RuleMatch的优先级队列,向其间插入RuleMatch首要在2个机遇点:
这样的好处便是能够经过迭代次数有效约束优化时刻,但害处也十分显着,没有了top-down的路径,无法完结pruning,关于physical property的处理也难以优化。
2020 年 7 月MaxCompute(ODPS)团队向社区兼并了top-down优化的patch,使得Calcite成为一个真正意义上的cascades优化器,其内部完结便是参阅了Columbia的规划,并针对Calcite原有流程和结构进行适配,但并没有引进global epsilon pruning的机制。由于作者并不太熟悉Calcite的代码细节,这儿就浅尝辄止了,更多介绍可参阅这篇文章。
跟着大数据的涌现和实时剖析需求变得越来越重要,数据库系统关于杂乱查询的处理才能逐渐成为武器库的根本配备,作为履行计划的生成组件,优化器的功能性会对系统的核算才能发生质的影响。
cascades结构是理论上最为灵活且扩展性最强的优化器完结计划,但惋惜现在业界成熟的完结并不多,开源的更少。
看起来最值得研究的仍是GPORCA,后续笔者争取能写一些关于Orca的规划完结和代码剖析文章,敬请期待。