天翼云代理,天翼云代理商,北京代理商
天翼云2.5折专线:18510009100/18510009200(全国市话)
 修改搜图
修改搜图
 修改搜图
修改搜图
 修改搜图
修改搜图
 修改搜图
修改搜图
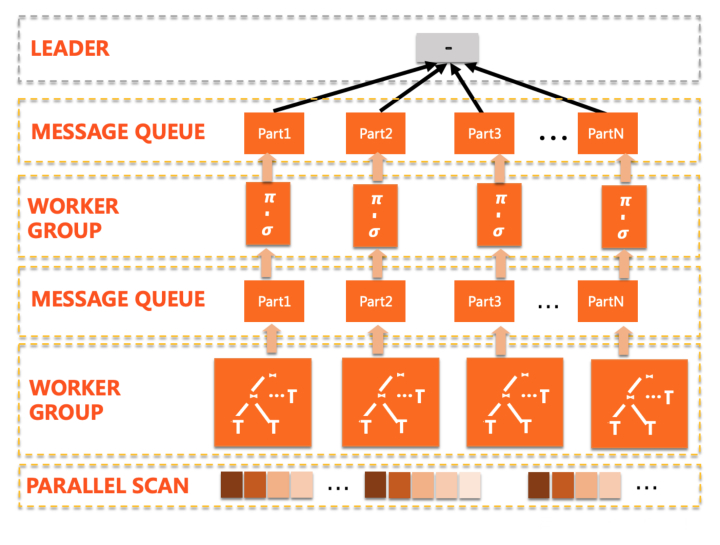 修改搜图
修改搜图
SELECT t1.a, sum(t2.b)FROMt1 JOIN t2 ON t1.a = t2.aJOIN t3 ON t2.c = t3.cGROUP BY t1.aORDER BY t1.aLIMIT 10;
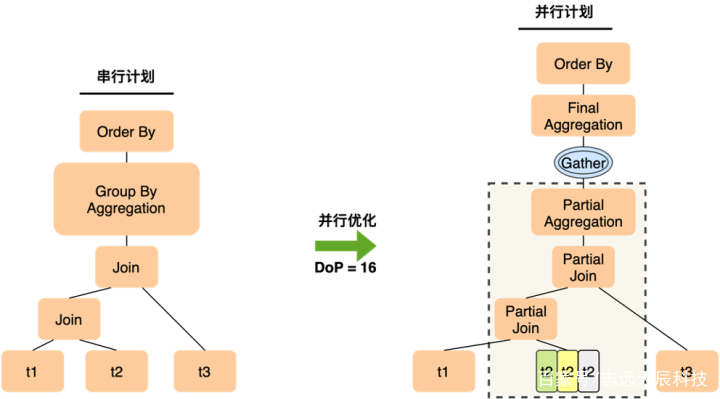 修改搜图
修改搜图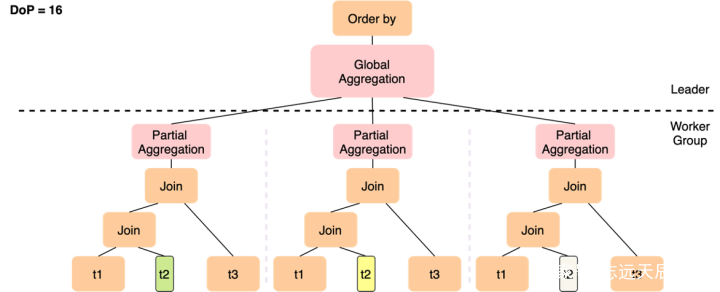 修改搜图
修改搜图
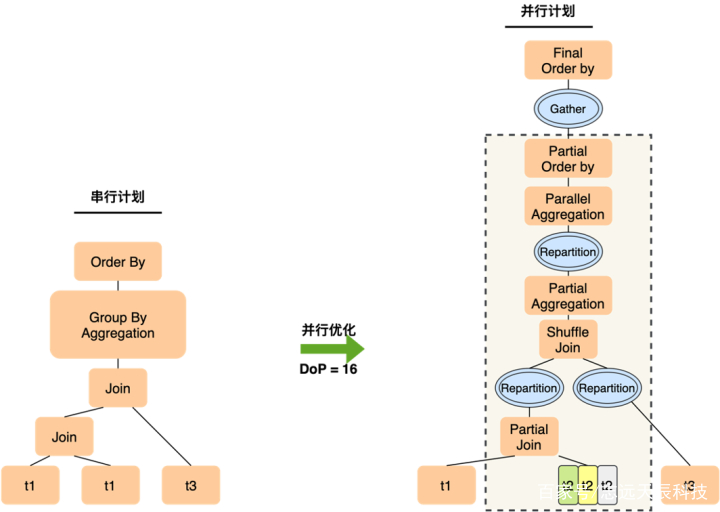 修改搜图
修改搜图
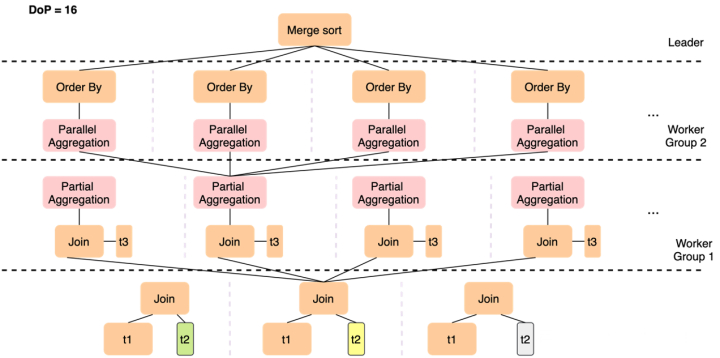 修改搜图
修改搜图
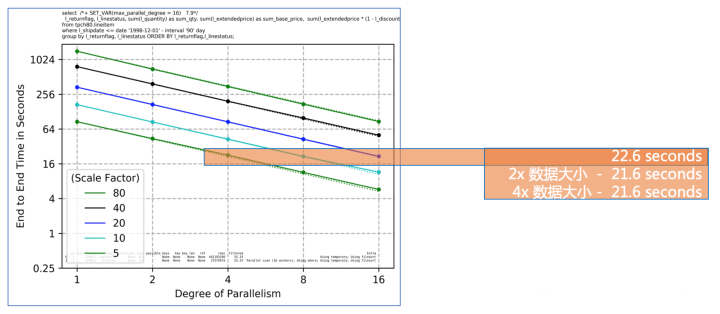 修改搜图
修改搜图
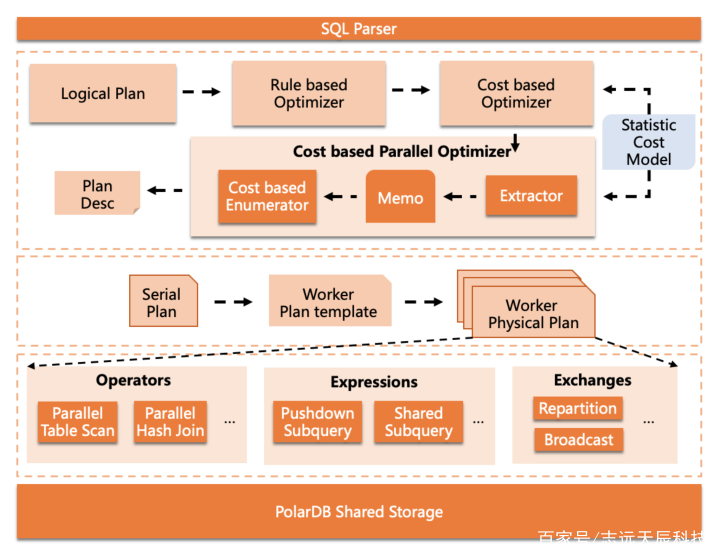 修改搜图
修改搜图
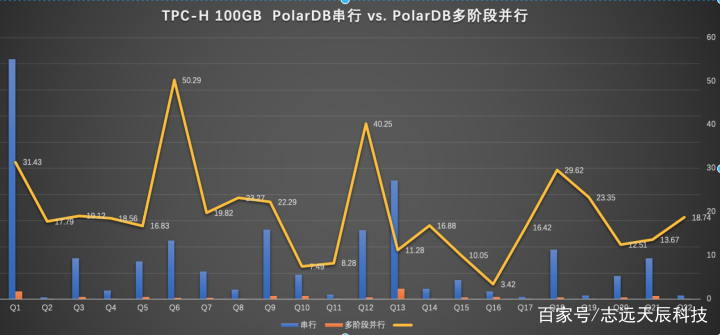 修改搜图
修改搜图
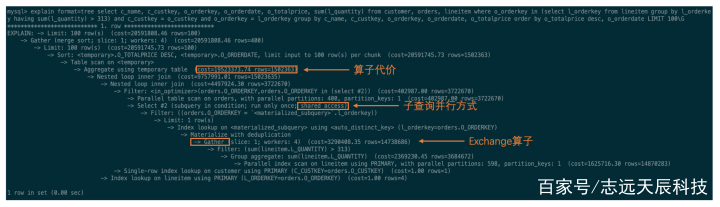 修改搜图
修改搜图
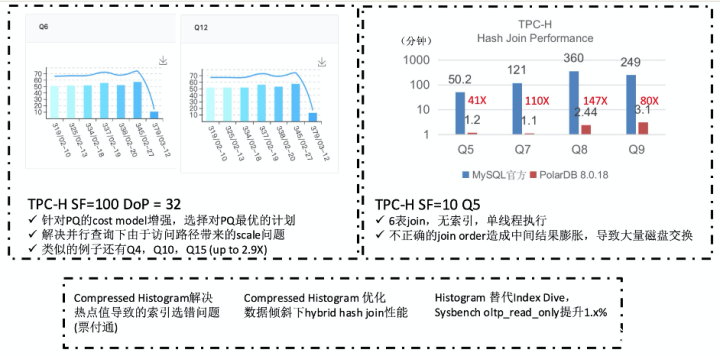 修改搜图
修改搜图
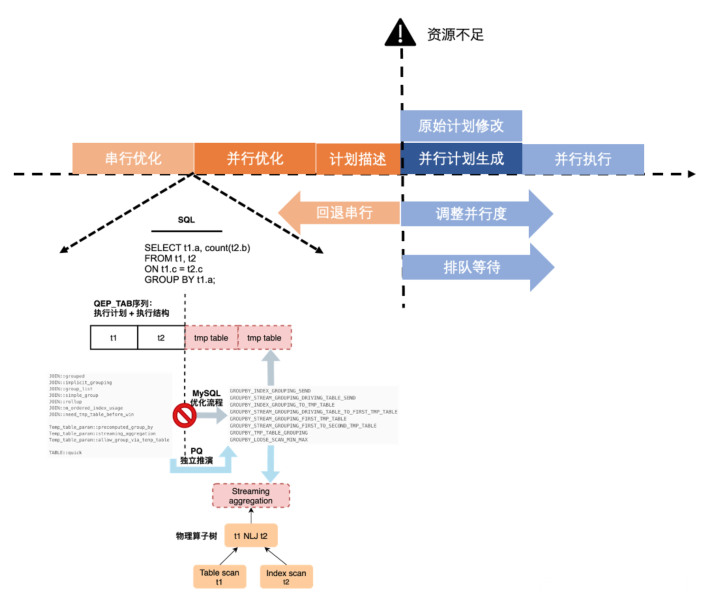 修改搜图
修改搜图
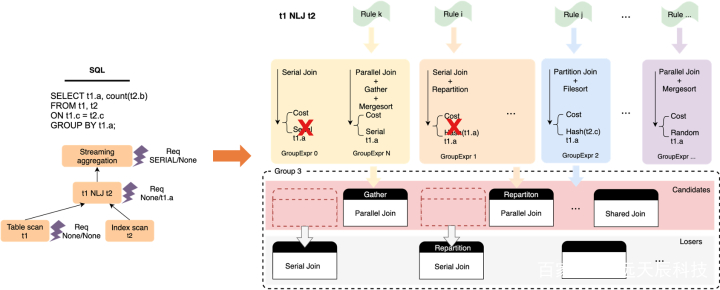 修改搜图
修改搜图
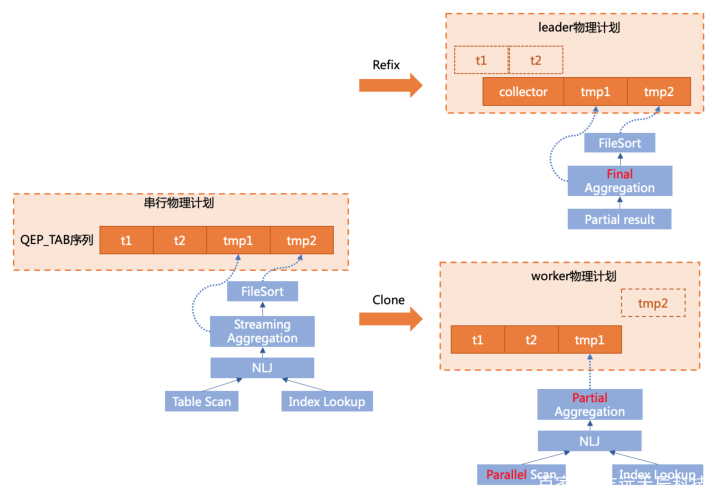 修改搜图
修改搜图
SELECT t1.a, sum(t2.b) sumbFROM t1 join t2ON t1.c = t2.cGROUP BY t1.aORDER BY sumb;
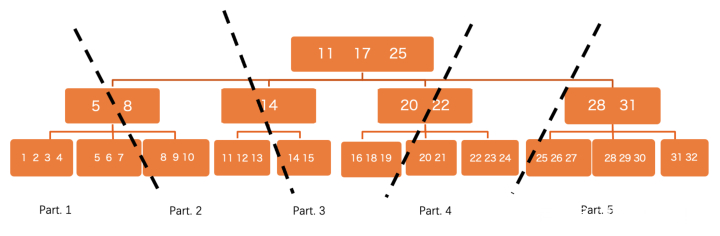 修改搜图
修改搜图
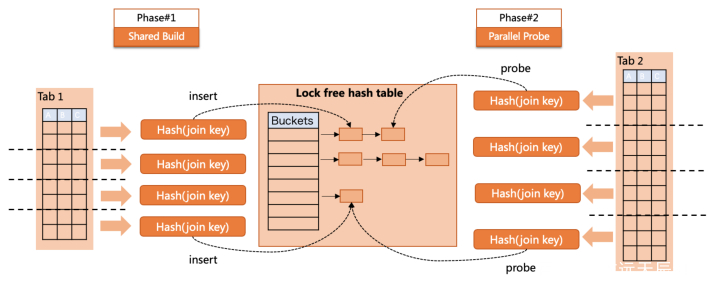 修改搜图
修改搜图
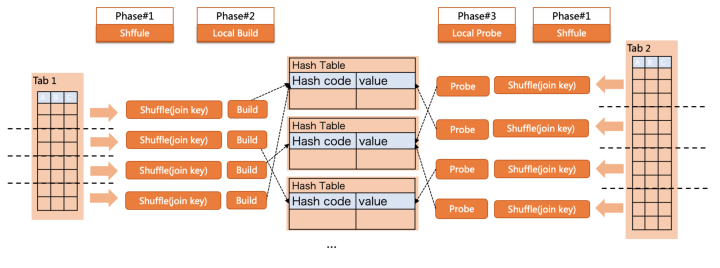 修改搜图
修改搜图
SELECT c1 FROM t1WHERE EXISTS ( SELECT c1 FROM t2 WHERE t2.a = t1.a <= EXISTS subquery )ORDER BY c1LIMIT 10;
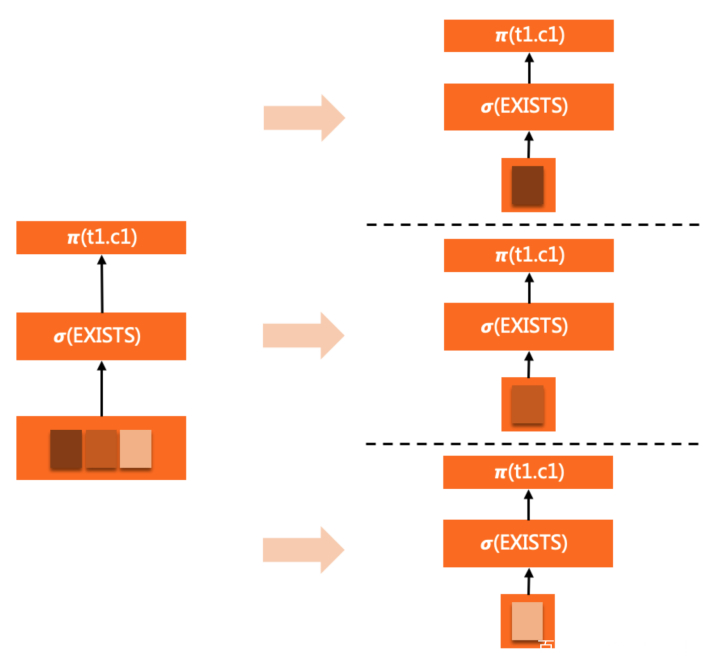 修改搜图EXISTS子查询完好的clone到各个worker中,跟着WHERE条件的evaluation重复触发履行。
修改搜图EXISTS子查询完好的clone到各个worker中,跟着WHERE条件的evaluation重复触发履行。
SELECT c1 FROM t1WHERE t1.c2 IN ( SELECT c2 FROM t2 WHERE t2.c1 < 15 <= IN subquery )ORDER BY c1LIMIT 10;
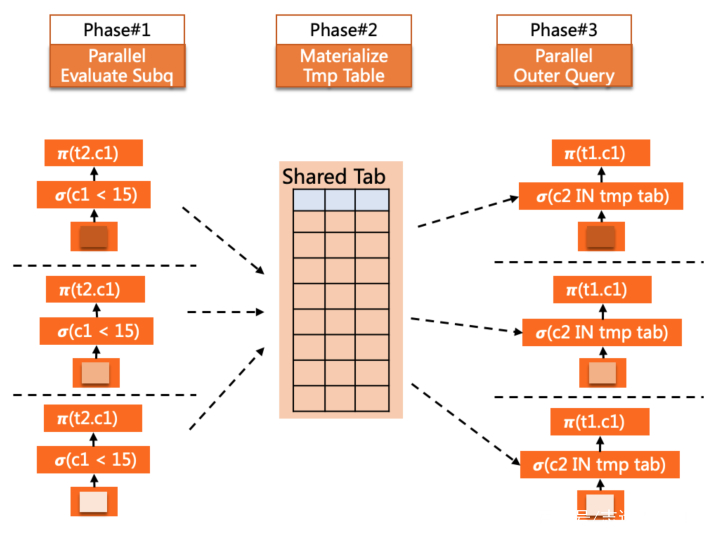 修改搜图
修改搜图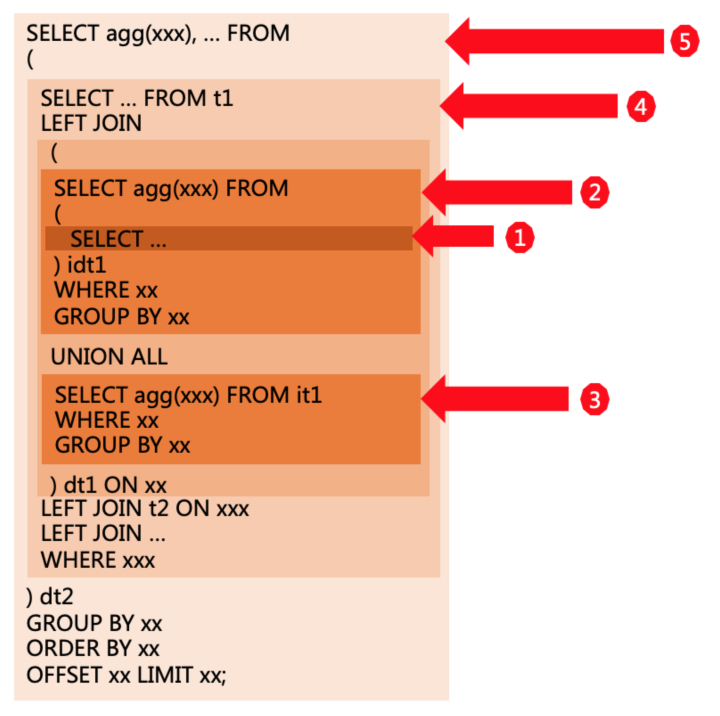 修改搜图
修改搜图
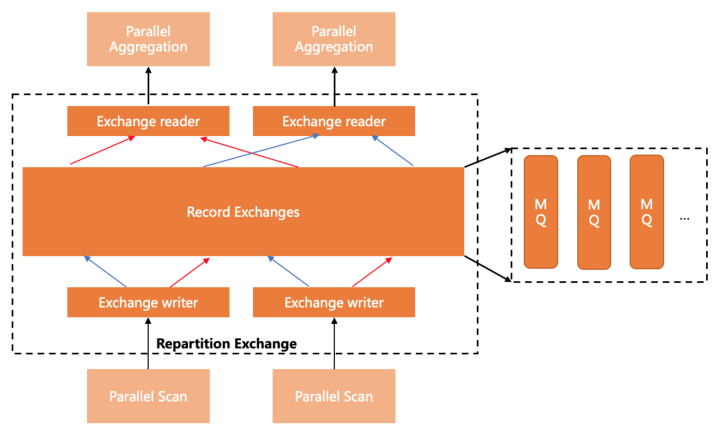 修改搜图
修改搜图
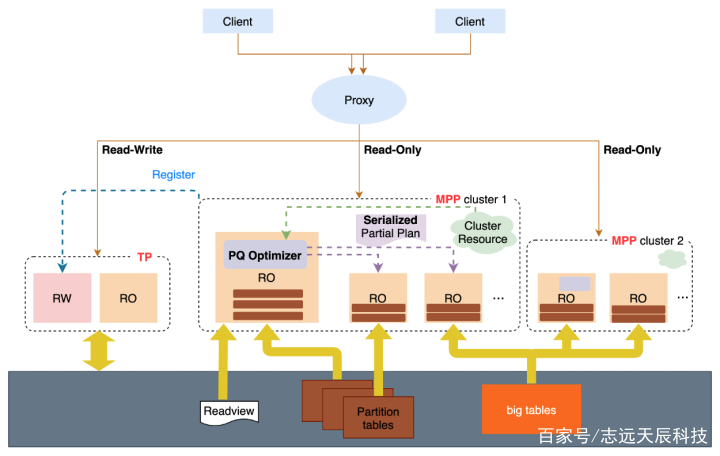 修改搜图
修改搜图